SELECT CAR_ID, ROUND(AVG(DATEDIFF(END_DATE,START_DATE)+1), 1) AS AVERAGE_DURATION
FROM CAR_RENTAL_COMPANY_RENTAL_HISTORY
GROUP BY CAR_ID
HAVING AVG(DATEDIFF(END_DATE,START_DATE)+1) >= 7
ORDER BY AVERAGE_DURATION DESC, CAR_ID DESC📍 문제
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr

📍 풀이
고려해야할 조건들을 살펴보자!
1. 평균 대여 기간이 7일 이상인 자동차들
2. 평균 대여 기간은 소수점 두번째 자리에서 반올림
3. 평균 대여 기간 기준 내림차순 정렬
이 문제의 핵심은 (나는 이걸 놓쳐서 틀렸다)
1. GROUP BY, HAVING 절, AVG() 활용하여 평균 대여 기간 7일 이상인 자동차들만 가져오기
GROUP BY CAR_ID
HAVING AVG(DATEDIFF(END_DATE,START_DATE) + 1) >= 72. ROUND 활용하여 평균 대여 기간 소수점 두번째 자리에서 반올림
SELECT CAR_ID, ROUND(AVG(DATEDIFF(END_DATE,START_DATE)+1), 1) AS AVERAGE_DURATION3. ORDER BY 활용하여 평균 대여 기간 기준 내림차순 정렬
ORDER BY AVERAGE_DURATION DESC, CAR_ID DESC
이렇게 해서 잘 쓴 것 같았지만,,,, 틀렸다...
❌ 틀린 코드 ❌
SELECT CAR_ID, ROUND(AVG(DATEDIFF(END_DATE,START_DATE)), 1) AS AVERAGE_DURATION
FROM CAR_RENTAL_COMPANY_RENTAL_HISTORY
GROUP BY CAR_ID
HAVING AVG(DATEDIFF(END_DATE,START_DATE)) >= 7
ORDER BY AVERAGE_DURATION DESC, CAR_ID DESC
그 이유는
총 대여 기간 : 날짜 간의 차이 + 1
쩝,,,
📍 전체 정답 코드
SELECT CAR_ID, ROUND(AVG(DATEDIFF(END_DATE,START_DATE)+1), 1) AS AVERAGE_DURATION
FROM CAR_RENTAL_COMPANY_RENTAL_HISTORY
GROUP BY CAR_ID
HAVING AVG(DATEDIFF(END_DATE,START_DATE)+1) >= 7
ORDER BY AVERAGE_DURATION DESC, CAR_ID DESC'SQL' 카테고리의 다른 글
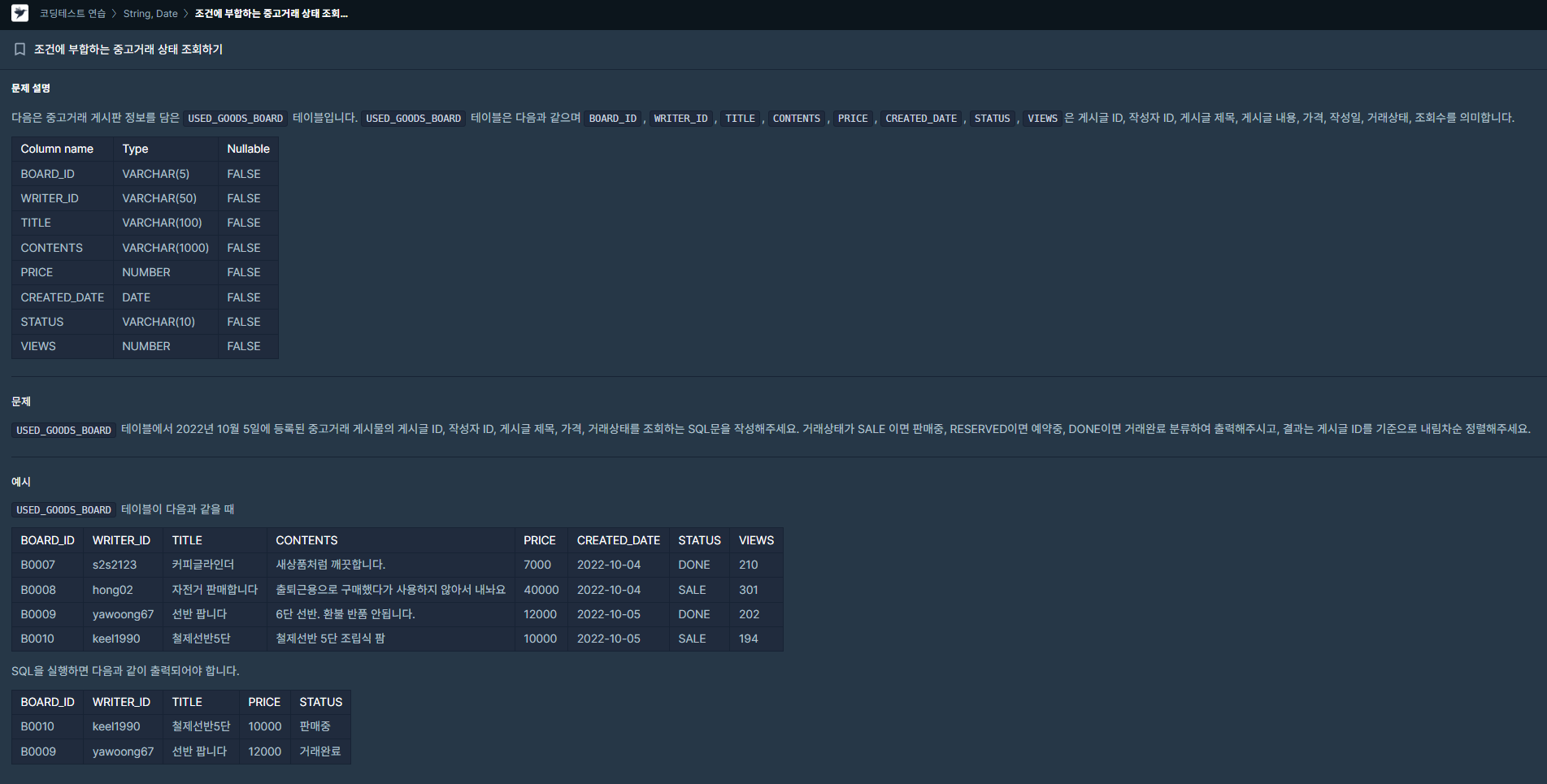
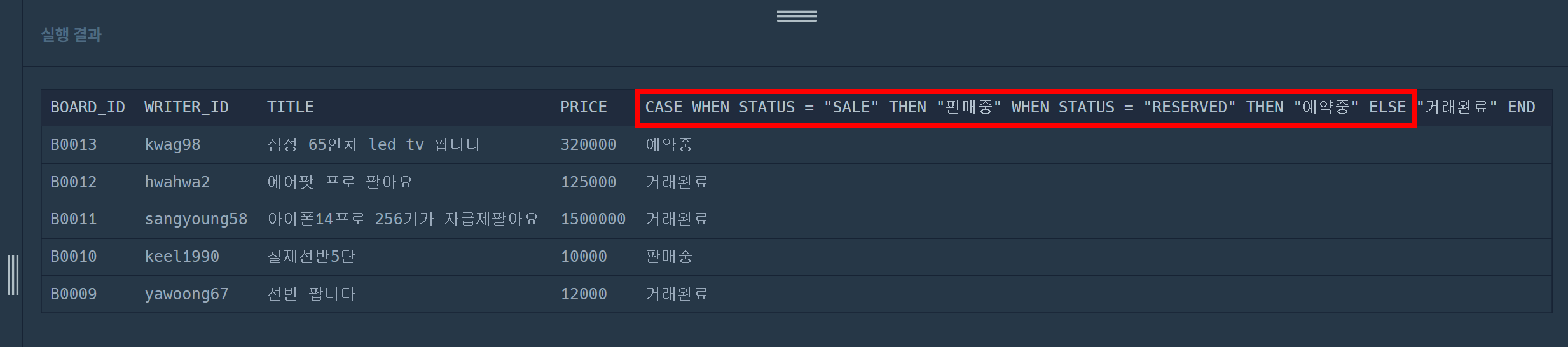
| [SQL] (프로그래머스/MySQL/Level 2)_ 조건에 부합하는 중고거래 상태 조회하기 (0) | 2024.02.04 |
|---|---|
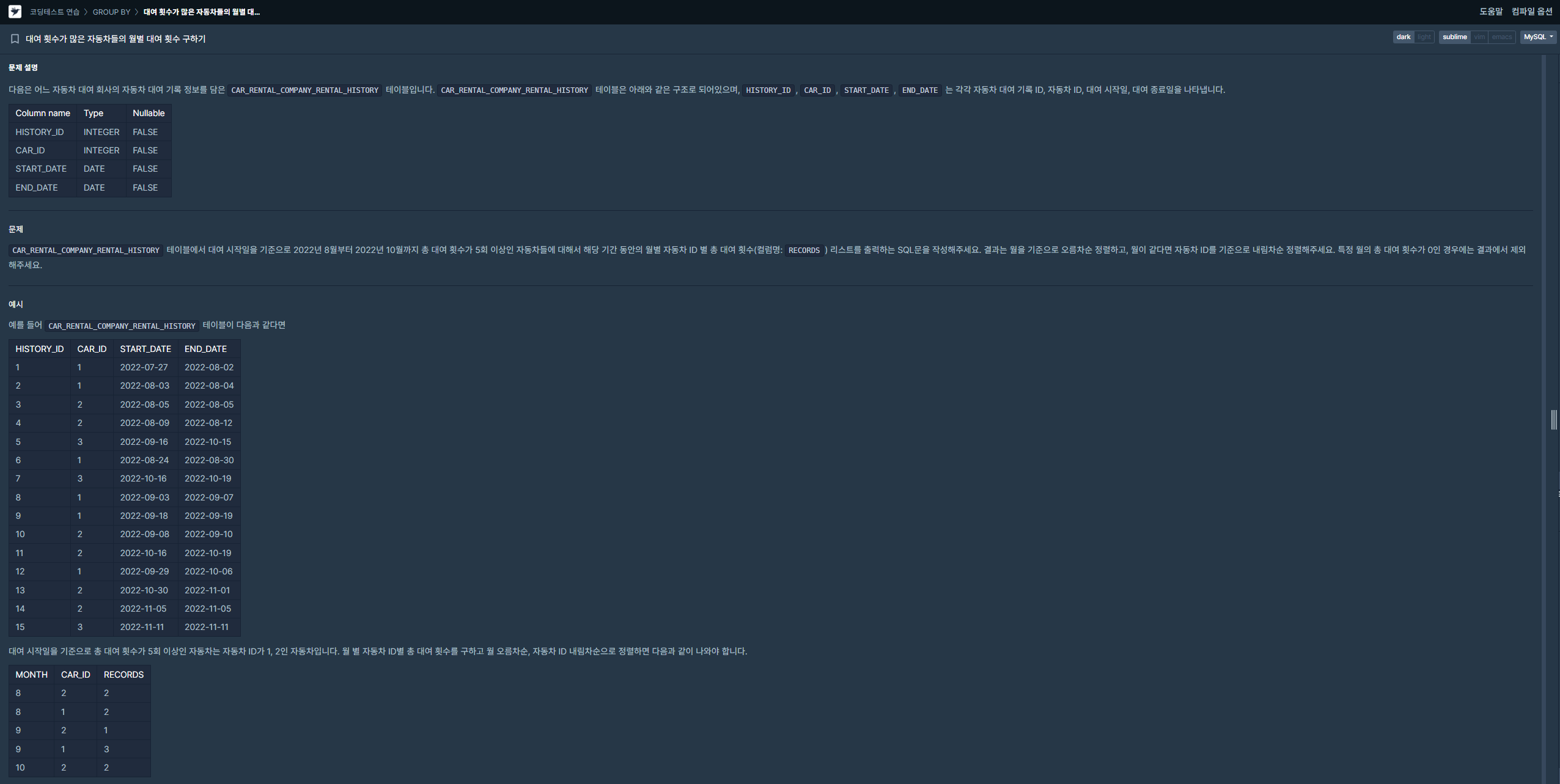
| [SQL] (프로그래머스/MySQL/Level 3)_대여 횟수가 많은 자동차들의 월별 대여 횟수 구하기 (0) | 2024.01.28 |
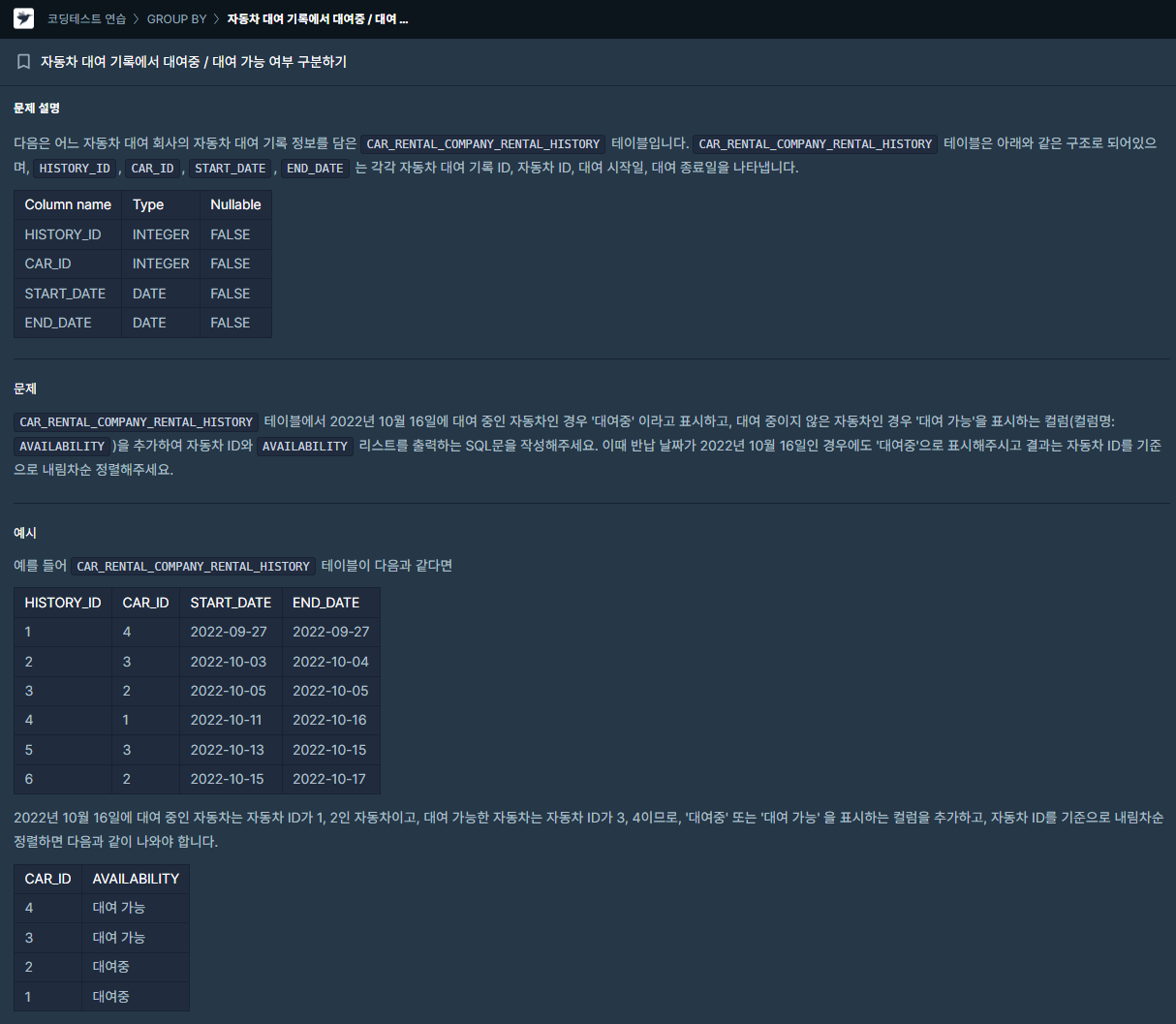
| [SQL] (프로그래머스/MySQL/Level 3)_자동차 대여 기록에서 대여중 / 대여 가능 여부 구분하기 (0) | 2024.01.28 |
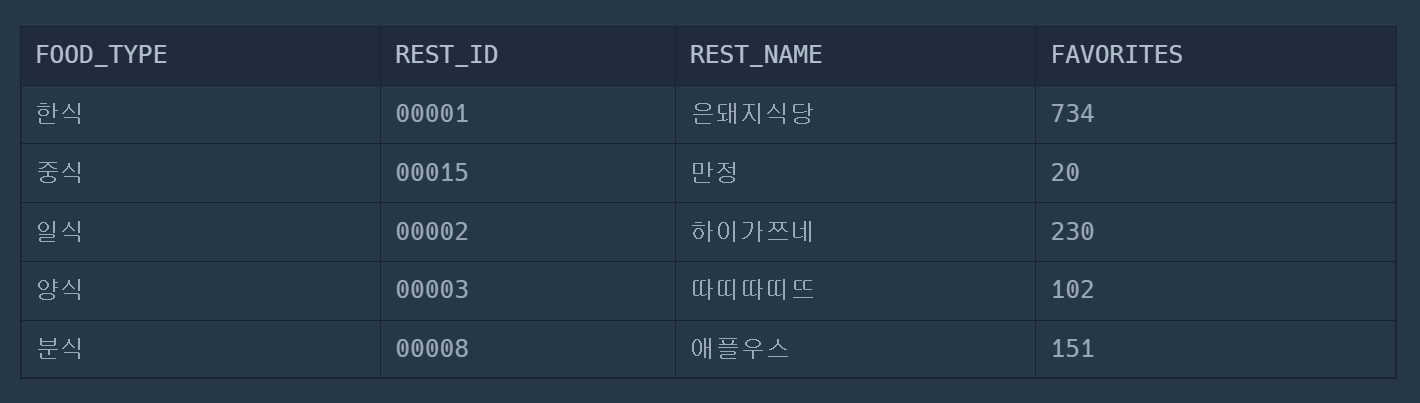
| [SQL] (프로그래머스/MySQL/Level 3)_즐겨찾기가 가장 많은 식당 정보 출력하기 (0) | 2024.01.26 |
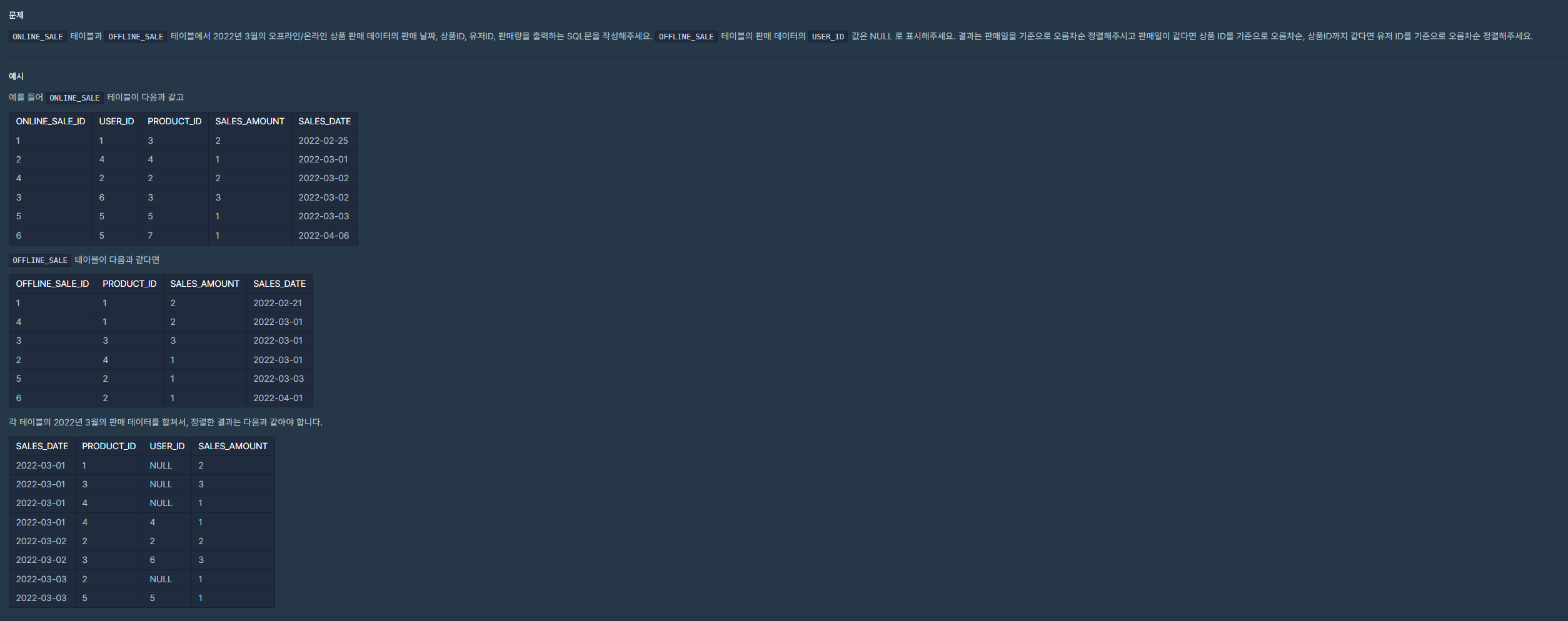
| [SQL] (프로그래머스/MySQL/Level 4)_오프라인/온라인 판매 데이터 통합하기 (0) | 2024.01.22 |