📍 문제
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr

📍 풀이
고려해야 할 조건들부터 살펴보자!
1. 음식 종류별로 즐겨찾기 수가 가장 많은 식당의
=> 음식 종류마다 즐겨찾기 수가 가장 많은 식당 하나만 가져오기
2. 음식 종류를 기준으로 내림차순 정렬
내가 처음 쓴 코드는
1번 조건을 위해 MAX()를 이용하였다.
SELECT FOOD_TYPE, REST_ID, REST_NAME, MAX(FAVORITES) AS FAVORITES
FROM REST_INFO
GROUP BY FOOD_TYPE
ORDER BY FOOD_TYPE DESC이 코드를 실행하면 다음과 같은 결과가 나온다.

얼핏 보면 정답과 일치해 보이지만, 일식의 경우 정답과 다른 결과가 나온다.
이런 결과가 나오는 이유는
GROUP BY로 묶으면 가장 상단에 있는 데이터들을 임의로 가져온다.
따라서, SELECT에 MAX를 해도 최대값을 가져오는 게 아니라 그룹화된 테이블 가장 상단에 있는 값을 가져온다.
그렇다면 어떻게 해야 할까?
이 문제의 핵심은,
❗ 서브 쿼리를 사용해 최대값을 따로 찾아주어야 한다 ❗
SELECT FOOD_TYPE, REST_ID, REST_NAME, FAVORITES
FROM REST_INFO
WHERE (FOOD_TYPE, FAVORITES)
IN
(SELECT FOOD_TYPE, MAX(FAVORITES)
FROM REST_INFO
GROUP BY FOOD_TYPE)
ORDER BY FOOD_TYPE DESC
복잡해 보이는 이 쿼리가 어떤 순서로 진행되는지 살펴보자.
그 전에 참고할 SQL의 쿼리 실행 순서 관련 :
sql 의 쿼리 실행 순서
서브쿼리에 대한 문제를 풀다가 왜 서브쿼리를 써야하지 이해가 안됬는데 실행 순서떄문에 그런것이였다 ㅇㅁㅇ 그런 기념으로 날잡고 한번 실행순서 정리해봅니다 1.FROM 절 (+ Join) 가장 먼저
monawa.tistory.com
1. FROM REST_INFO : REST_INFO 테이블에서 데이터 가져오기
2. GROUP BY FOOD_TYPE : 'FOOD_TYPE' 칼럼을 기준으로 데이터 그룹화
=> 각 'FOOD_TYPE'의 식당들이 하나의 그룹으로 묶임
3. SELECT FOOD_TYPE, MAX(FAVORITES) : 각 그룹에서 'FAVORITES'의 최대갑승ㄹ 찾고 해당하는 'FOOD_TYPE' 선택
4. IN : 서브 쿼리가 완성되었고, 이 결과가 바깥쪽 쿼리의 WHERE 조건과 매치되는지 확인하기 위해 사용
5. WHERE (FOOD_TYPE, FAVORITES) IN : 바깥 쿼리에서 'FOOD_TYPE'과 'FAVORITES'가 내부 쿼리의 결과와 일치하는 행들을 선택합니다. 이는 각 'FOOD_TYPE' 마다 즐겨찾기 수가 가장 많은 식당만을 추출하는 작업
6. SELECT FOOD_TYPE, REST_ID, REST_NAME, FAVORITES : 선택된 행들에서 'FOOD_TYPE', 'REST_ID', 'REST_NAME', 'FAVORITES' 칼럼을 선택
7. ORDER BY FOOD_TYPE DESC : 결과를 'FOOD_TYPE' 을 기준으로 내림차순으로 정렬
'SQL' 카테고리의 다른 글
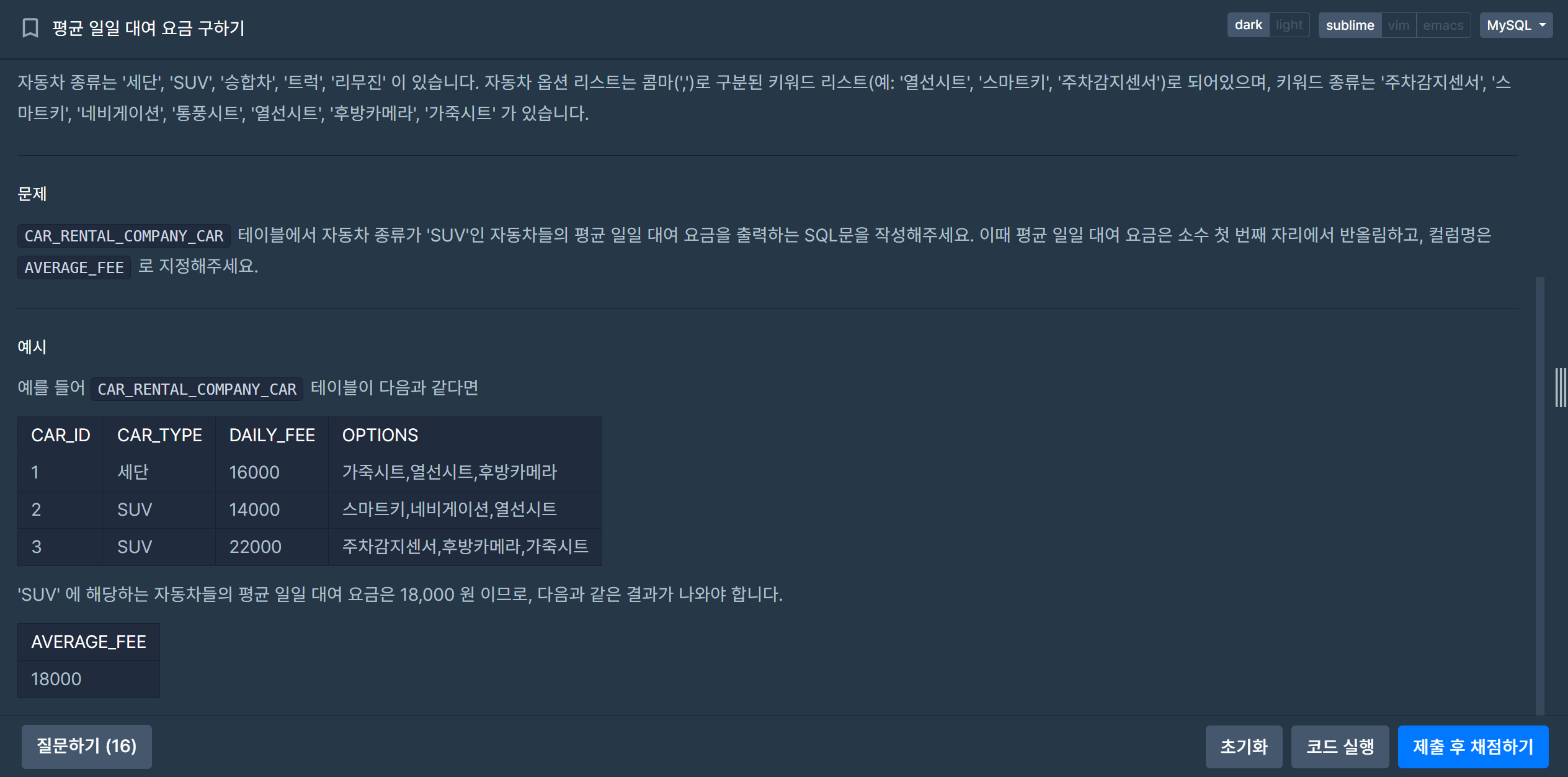
| [SQL] (프로그래머스/MySQL/Level 3)_대여 횟수가 많은 자동차들의 월별 대여 횟수 구하기 (0) | 2024.01.28 |
|---|---|
| [SQL] (프로그래머스/MySQL/Level 3)_자동차 대여 기록에서 대여중 / 대여 가능 여부 구분하기 (0) | 2024.01.28 |
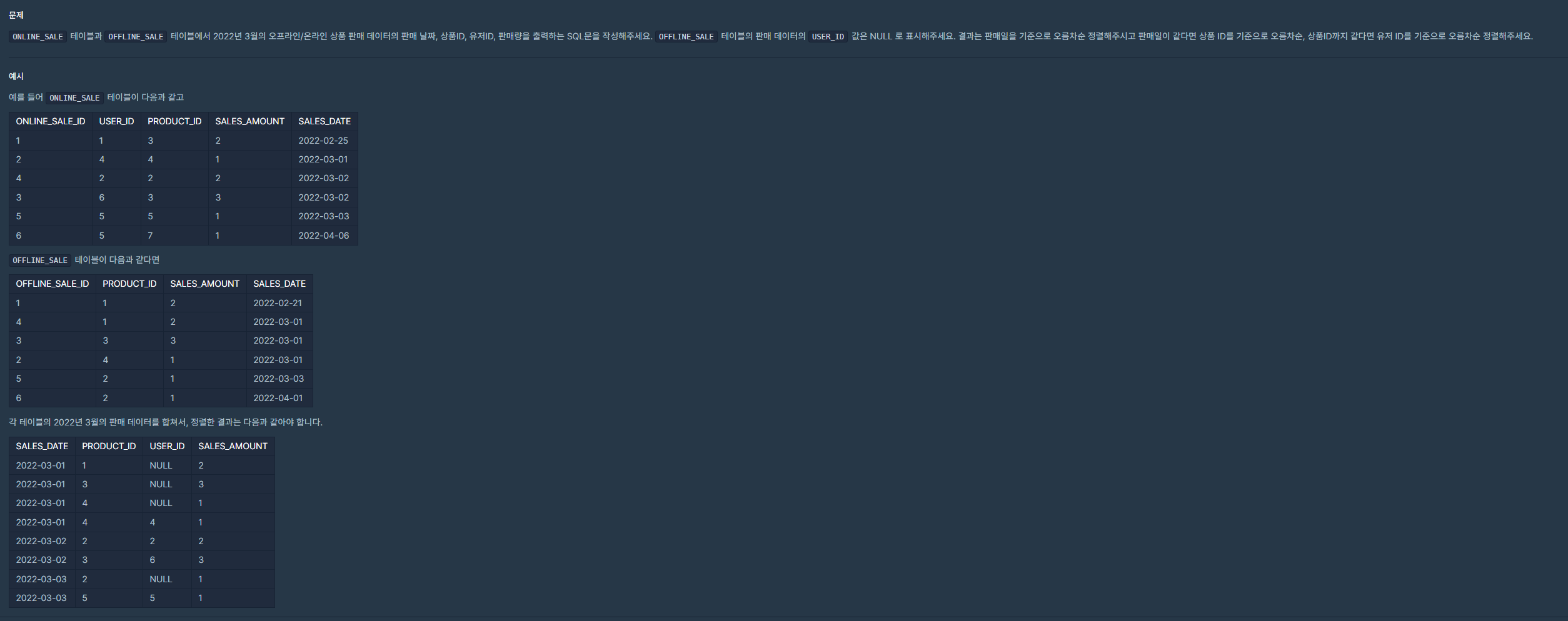
| [SQL] (프로그래머스/MySQL/Level 4)_오프라인/온라인 판매 데이터 통합하기 (0) | 2024.01.22 |
| [SQL] LIKE() 함수 : 특정 문자 포함해서 검색 (MYSQL) (0) | 2024.01.17 |
| [SQL] GROUP BY 와 HAVING절 (MYSQL) (0) | 2024.01.17 |